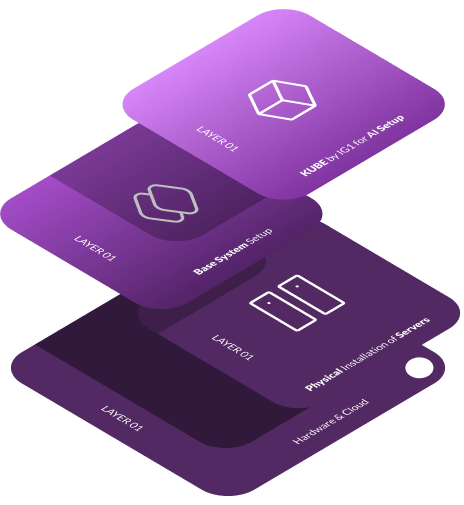
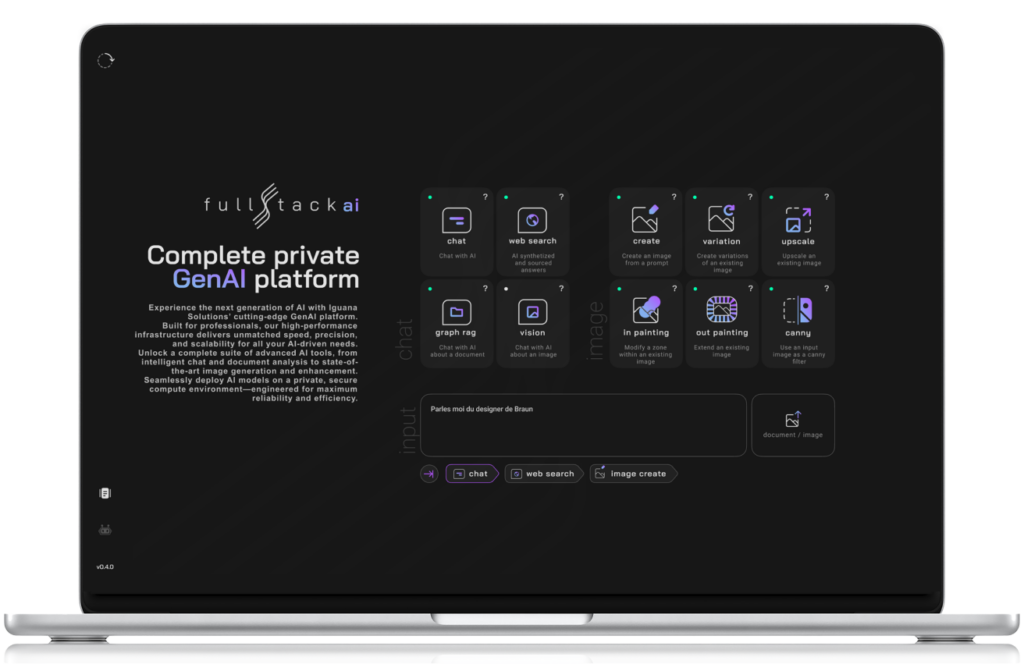
We offer innovative Gen AI platforms that make AI infrastructure effortless and powerful. Harnessing NVIDIA’s H100 and H200 GPUs, our solutions deliver top-tier performance for your AI needs.
Our platforms adapt seamlessly, scaling from small projects to extensive AI applications, providing flexible and reliable hosting. From custom design to deployment and ongoing support, we ensure smooth operation every step of the way. In today’s fast-paced AI world, a robust infrastructure is key. At Iguana Solutions, we’re not just providing technology; we’re your partner in unlocking the full potential of your AI initiatives. Explore how our Gen AI platforms can empower your organization to excel in the rapidly evolving realm of artificial intelligence.