Iguane Solutions est un expert en hébergement et externalisation d'infrastructures informatiques qui a besoin de connaître en temps réel l'état de toutes les infrastructures sous son contrôle.
L'évolution continue des différentes couches logicielles, l'arrivée de nouvelles pratiques de développement telles que la conteneurisation, les nouveaux outils de développement agile et les pratiques DevOps génèrent de plus en plus de données à collecter et à centraliser, afin d'agir et de réagir toujours plus rapidement. La mise en place de l'observabilité est la solution adoptée par nos équipes techniques pour mener à bien leurs missions.
Observabilité : Définition
L'observabilité est la capacité à observer le comportement d'un système. Pour y parvenir, le système doit être instrumenté sur les 3 piliers suivants :
Métriques: Mesure l'état de la plateforme et de ses services. Plus précisément, les métriques sont des éléments quantifiés mesurés à un moment donné et à une fréquence régulière, ce qui permet de tracer des courbes d'évolution dans le temps.
Journaux: fichiers texte contenant toutes les informations relatives à l'état de l'application : nouvelles connexions, messages d'erreur, messages destinés aux développeurs. Les journaux d'application sont utiles pour rechercher les causes profondes des incidents, en complément des mesures.
Traces: Suivi horizontal d'une demande à travers plusieurs applications. Utile pour comprendre le comportement d'une application et l'améliorer.
Un autre terme souvent utilisé dans ce contexte est celui de "surveillance". La surveillance est l'action de suivre le comportement d'un système.
Il convient de noter que la mise en place d'une collecte de traces d'application est intrusive et peut avoir un impact significatif sur les performances.
En bref :
- Observabilité : le concept d'observation du comportement d'une application à travers 3 éléments : les métriques, les journaux et les traces d'application.
- Supervision : l'action de surveiller et, si nécessaire, d'alerter sur le comportement anormal d'une application ou d'un système.
Observabilité : Mise en œuvre
En 2018, notre système de supervision historique basé sur Naemon et Graphite commençait à montrer quelques limites et surtout ne couvrait plus l'ensemble de nos besoins pour garantir un niveau de service optimal pour nous et nos clients. Le site stack devenait obsolète et toute modification pour intégrer de nouvelles plateformes était complexe. De plus, notre système ne surveillait que les métriques "système" de l'équipement.
Pour ces raisons, nous avons décidé de mettre en œuvre une nouvelle solution de métrologie avec les spécifications suivantes :
- Collecter des données sur le matériel
- Collecte des métriques du système (vue des ressources du système : CPU, RAM, stockage, réseau)
- Collecter les métriques de service requises par les applications (nginx, apache, php, mysql, mongoDB, elasticsearch, Docker, Kubernetes, ...).
- Collecter les journaux du système
- Collecter les journaux de service
- Contrôler la quantité et/ou la cardinalité de chaque métrique
- Système multi-locataires (isolation du client)
- Interface de visualisation pour nous et nos clients
- Rétention très longue des données, si possible illimitée
La section "Traces d'applications" ne fait pas partie du cahier des charges, car les traces d'applications collectent des informations directement à partir du code source des applications que nous hébergeons.
À l'instar d'un service PaaS (Platform as a Service), nous fournissons, par le biais de l'externalisation, des plateformes spécifiques aux besoins de nos clients. Une plateforme regroupe la couche infrastructure, la partie système (OS + services applicatifs) et toute l'observabilité de l'ensemble Infrastructure + Système. La partie logicielle (code d'application) reste sous la responsabilité de nos clients. Cependant, sur demande, dans le cadre d'une investigation ou à des fins d'optimisation, nous pouvons proposer de déployer un outil de collecte de traces applicatives afin d'optimiser le fonctionnement de l'ensemble de la plateforme.
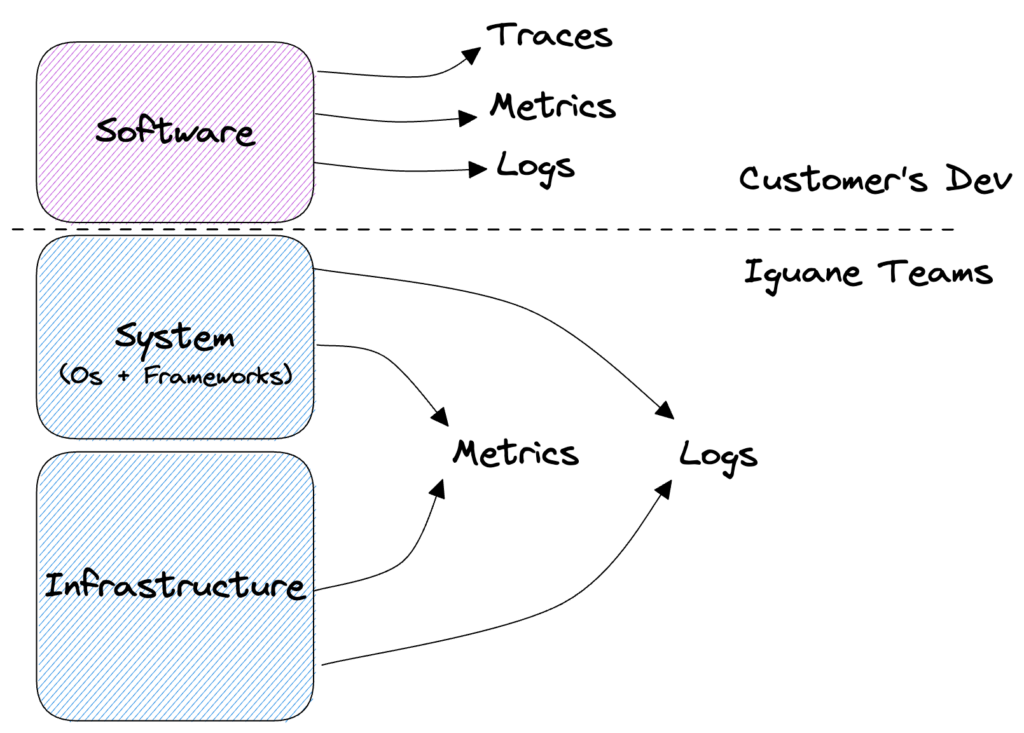
Figure : Représentation des différentes couches d'une application logicielle avec leurs éléments d'observabilité respectifs.
Sur la base des spécifications précédentes, nous avions deux options :
- Utiliser un outil d'observabilité du marché comme Datadog, Dynatrace, Splunk par exemple
- S'appuyer sur un ensemble d'outils Open Source tels que Prometheus, VictoriaMetrics, InfluxDB, Grafana et développer les parties manquantes.
Après une étude rapide, nous avons obtenu le tableau comparatif suivant :
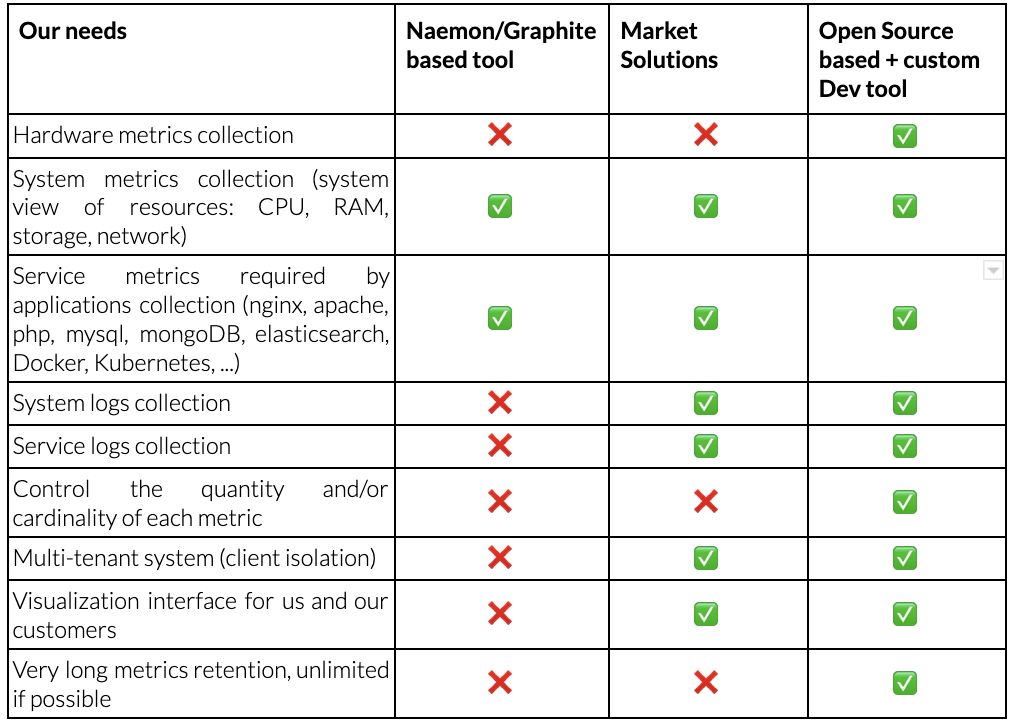
La colonne "Open Source + outil basé sur le développement" remporte le vote en tant qu'option la plus malléable. Les développements internes nous permettent d'ajouter des exigences qui ne sont pas présentes dans les solutions open source :
- Lier le logiciel sélectionné,
- Échanges sécurisés (mise en place de TLS entre chaque composant)
- Isoler les clients.
- Disposer de notre propre agent pour collecter les métriques et les logs
Cette combinaison de solutions Open Source et de développements internes est la seule qui réponde réellement à nos besoins en termes de modularité, d'intégration des mesures matérielles, de longue durée de rétention et de coût total inférieur à celui d'une solution SaaS sur le marché.
Cette option nous permet également de contrôler entièrement la chaîne de traitement de l'information, de la génération au traitement et au stockage.
Ce projet interne s'appelle Sismology.
Architecture et fonctionnement de la sismologie
L'architecture et la logique de fonctionnement de Sismology restent très simples :
- Agent de collecte des mesures et des journaux sur tous les équipements
- 2 appliances (redondance requise) par organisation cliente : serveurs avec Prometheus (collecte de métriques) et Fluentd (collecte de logs)
- Victoria Metrics cluster (centralisation de toutes les mesures avec identification du client pour l'isolement) et Loki (centralisation des journaux).
- Dans le cadre des mesures Victoria cluster , nous avons développé deux services pour soutenir la gestion automatique et sécurisée de l'isolement des clients :
- Sismology Ingester : qui insère des mesures pour un client donné sur la base des identifiants de l'appliance Sismology du client.
- Seismology Selecter : fait de même pour sélectionner les bonnes mesures pour l'interface de visualisation.
- Visualisation via des tableaux de bord Grafana avec gestion par l'organisation du client.
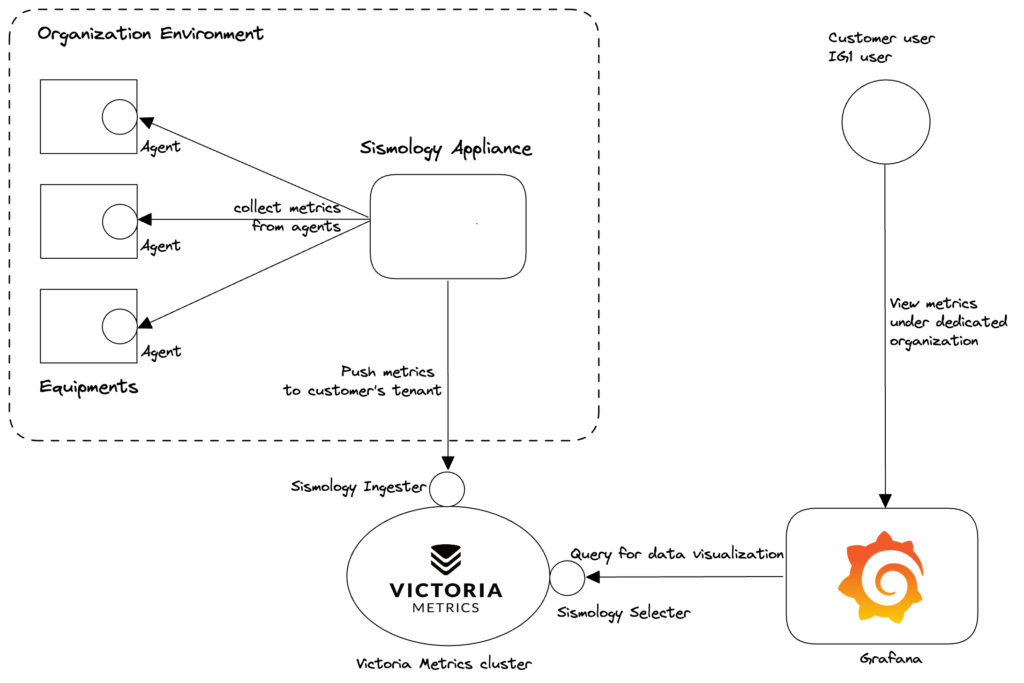
Figure : Diagramme de flux des mesures, de l'équipement à la visualisation en passant par la collecte
Pour la collecte des métriques, nous avons développé un ensemble de plugins adaptés à chaque type de service mesuré : système, matériel, mysql, php, apache, etc. Chaque agent active les plugins nécessaires uniquement en fonction des services configurés sur l'appareil.
Pour centraliser les mesures, nous avons d'abord choisi d'utiliser InfluxDB comme outil d'agrégation des points de mesure. Cependant, nous avons rapidement été confrontés à des problèmes de performance qui se sont détériorés avec l'ajout de nouveaux équipements.
Après quelques recherches et quelques benchmarks supplémentaires, nous avons choisi VictoriaMetrics pour son agrégation de points, sa compatibilité avec Grafana et la possibilité de le déployer en "High Availability" cluster dans sa version OpenSource. De plus, VictoriaMetrics dispose d'excellentes capacités de déduplication et de compression des données qui s'améliorent au fil du temps : plus il y a de données, meilleure est la compression sans dégradation des performances. En outre, VictoriaMetrics permet de gérer facilement différentes organisations et donc d'isoler proprement les données. Enfin, VictoriaMetrics s'intègre parfaitement à Grafana, de sorte que la refonte de nos tableaux de bord de visualisation n'a pas été une tâche complexe.
Plus de détails techniques sur notre utilisation de VictoriaMetrics : https://medium.com/iguanesolutions/sismology-iguana-solutions-monitoring-system-f46e4170447f
Pour la section Logs, nous avons développé notre outil de collecte et de centralisation des logs autour de Fluentd (collecte) et Loki (centralisation). Loki est un outil développé par Grafana Labs et s'intègre parfaitement à Grafana pour faciliter la visualisation et la navigation dans les logs.
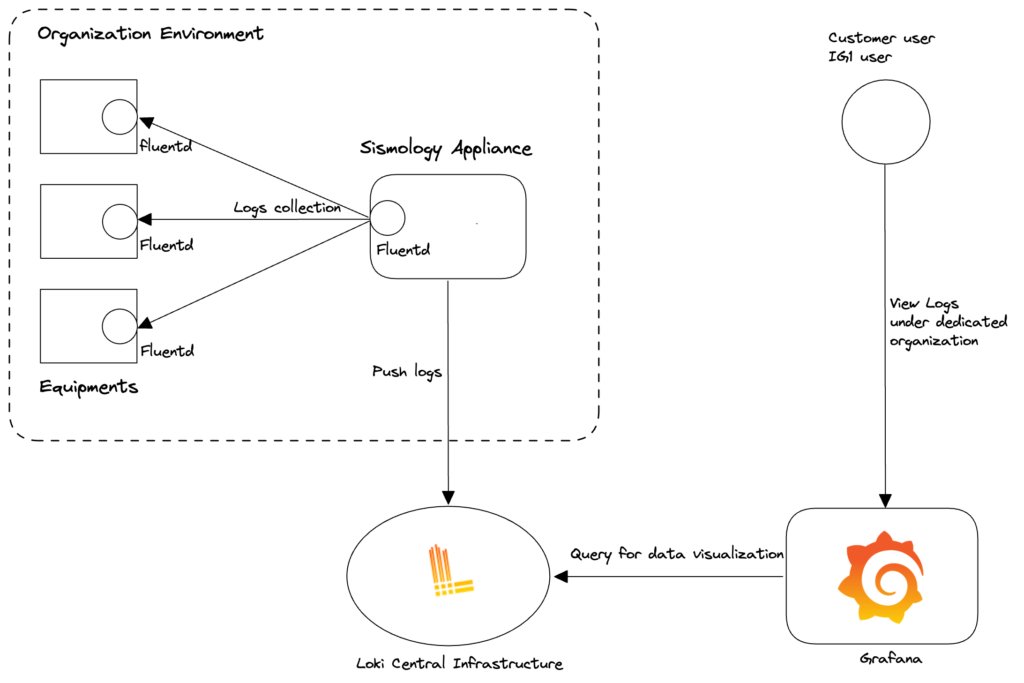
Figure : Diagramme de flux de données entre l'équipement, la collecte, le stockage et la visualisation
Ce dernier point est très important, car il facilite l'investigation en cas d'événement anormal. Sur le même tableau de bord Grafana, vous pouvez consulter les métriques et les journaux d'un système sur une période donnée.
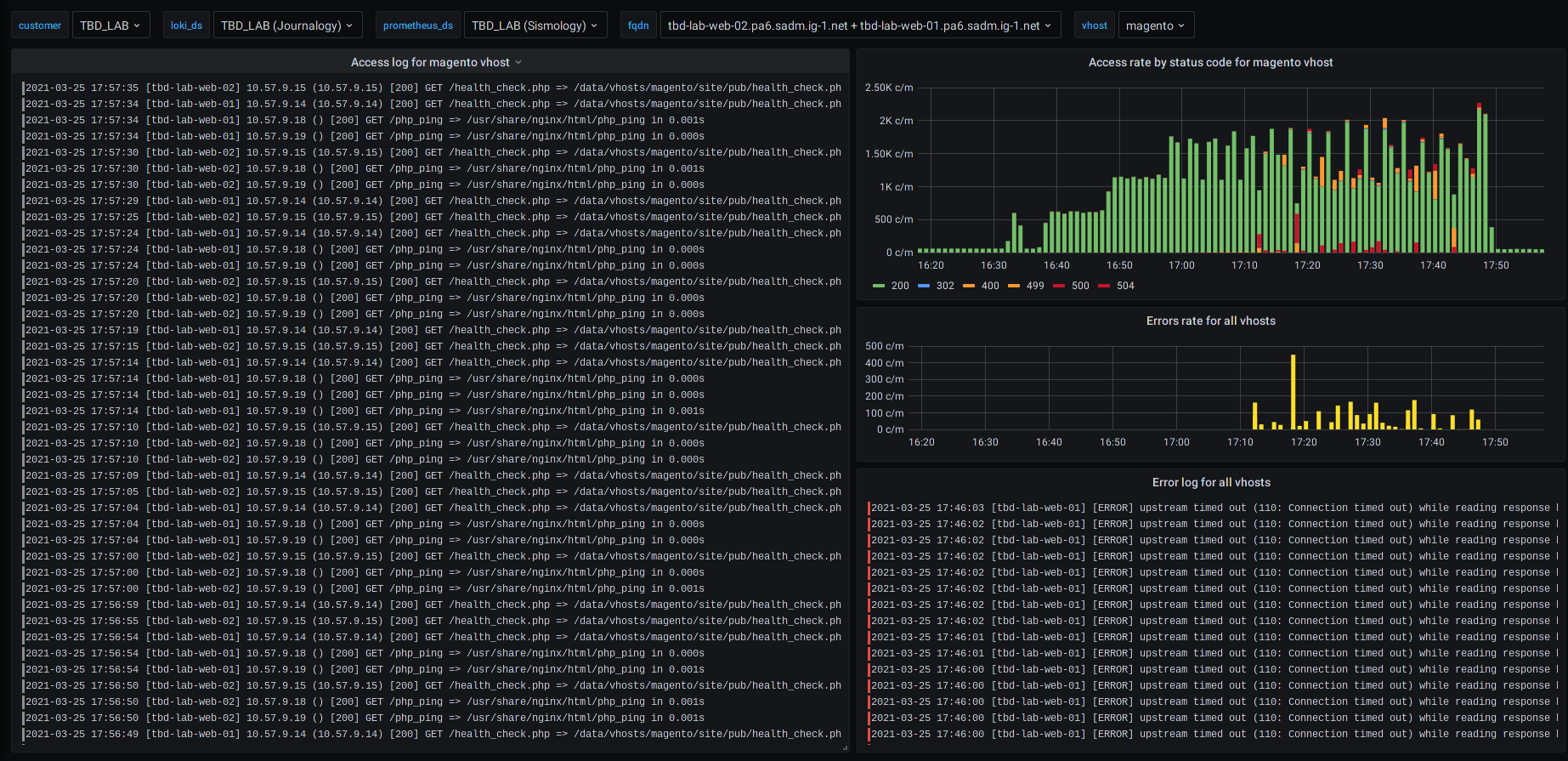
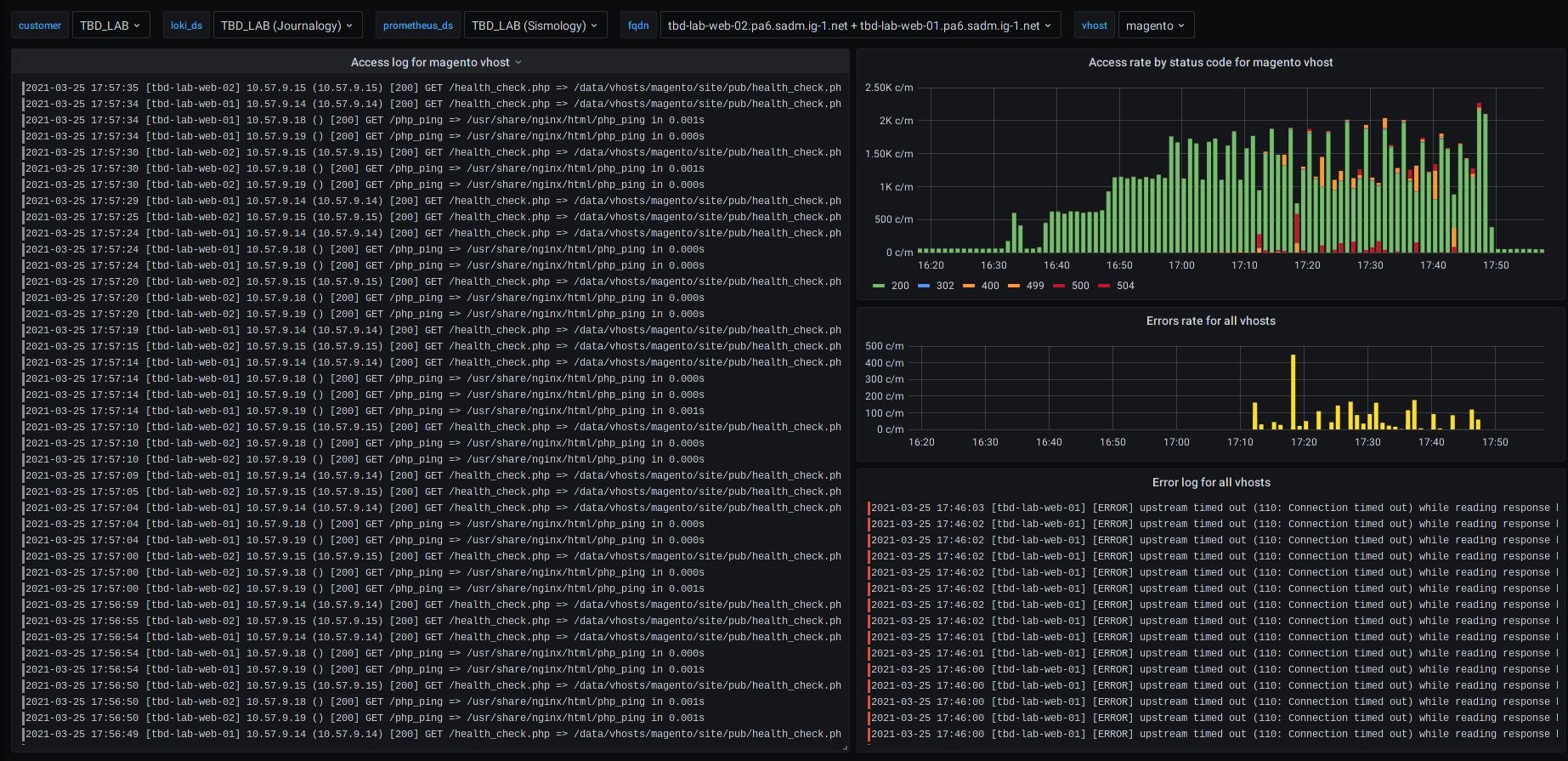 Figure : Exemples de différents tableaux de bord pour un site de commerce électronique (basé sur Magento)
Figure : Exemples de différents tableaux de bord pour un site de commerce électronique (basé sur Magento)
Par exemple, en cas d'erreur HTTP sur un serveur web, vous pouvez visualiser l'évolution de l'erreur et les journaux correspondants sur le même écran.
Nos équipes de support et d'experts permettent de gagner un temps précieux en cas d'événement anormal ou d'incident.
Nos avantages
Nous disposons d'une solution modulaire et sécurisée pour collecter et centraliser les métriques et les logs de toutes les plateformes. Grâce à ces données, nous avons pu développer un outil de supervision efficace.
Cet outil de gestion des alertes, directement intégré à Sismology, nous permet de déclencher un support ou une astreinte à tout moment, selon des critères définis par nos experts DevOps. Notre gestionnaire d'alertes est connecté à PagerDuty (déclenchement du support) ainsi qu'à Slack, où nous recevons des notifications en temps réel de toutes les alertes sur toutes les plateformes. Nous pouvons ainsi réagir immédiatement, quelle que soit la nature de l'alerte, et résoudre toute anomalie dans les plus brefs délais.
La mise en œuvre de la détection préventive des incidents et l'ajout de la détection des problèmes matériels par la sismologie ont considérablement réduit leur impact sur les systèmes des clients, ce qui a permis d'améliorer nos accords de niveau de service.
Conclusion
L'observabilité est une composante essentielle de toute solution de supervision de plateforme informatique. Pour nous, elle est au cœur de notre métier et nécessite la mise en place d'une solution fiable, efficace et adaptée à nos besoins.
Notre outil de métrologie se concentre donc sur deux des trois piliers de l'observabilité : les métriques et les journaux.
Avec Sismology, nous disposons d'un outil simple, efficace et facile à maintenir, avec le strict nécessaire pour rester le plus simple possible. Toutes nos équipes techniques contribuent à l'évolution de l'outil en ajoutant régulièrement de nouveaux plugins pour supporter un nouveau framework ou pour faire évoluer la collection d'un service existant. Après plus de 4 ans d'utilisation, nous avons testé un grand nombre de cas d'usage, et nous proposons à nos clients des tableaux de bord qui leur permettent de suivre facilement le comportement de leurs plateformes.
À retenir :
- Observabilité: 3 axes pour observer le comportement des applications : métriques, logs, traces applicatives
- Supervision: action de surveiller le comportement de la plateforme sur la base de l'observabilité
- La mise en œuvre nécessite le déploiement d'outils:
- soit des outils "clés en main" avec une large gamme d'intégrations : Datadog, Dynatrace, Splunk...
- ou des outils Open Source éprouvés, avec un travail de développement nécessaire pour les adapter : Prometheus, VictoriaMetrics, Fluentd, Grafana...
- Sismology: La solution de métrologie d'Iguane Solutions, qui se concentre sur les métriques et les logs essentiels des plates-formes du client à surveiller.
