


Unlock the full potential of your artificial intelligence projects with our AI-Optimized Hardware Solutions. Designed specifically to meet the demands of intensive AI workflows, our cutting-edge hardware range accelerates AI model training and inference , ensuring your innovations move from concept to reality faster than ever. With a focus on speed, efficiency, and scalability, our solutions provide the necessary power to handle complex computations and large datasets, seamlessly integrating into your existing infrastructure. Whether you’re developing advanced neural networks, automating complex processes, or analyzing vast amounts of data, our hardware is engineered to boost performance and reliability. Embrace the future of AI with the tools that give you the competitive edge, driving your organization towards new heights of innovation and success.
As AI technologies continue to evolve, the need for specialized hardware that can handle the intensive demands of AI computations becomes crucial. AI hardware refers to the advanced array of processors, including GPUs, TPUs, and custom AI accelerators, specifically engineered to efficiently manage the massive data processing and complex matrix operations typical of AI tasks.
These components are not just faster than traditional CPUs; they are designed from the ground up to accelerate AI model training and inference, providing the backbone for breakthroughs in machine learning and deep learning.
By significantly reducing processing times, AI hardware enables researchers and developers to iterate on models more quickly and deploy AI solutions faster, bringing AI innovations from lab to market with unprecedented speed.
Understanding the capabilities and benefits of AI hardware is essential for any organization looking to leverage artificial intelligence to its fullest. With these tools, businesses can harness powerful computational resources to unlock new possibilities in data analysis, predictive modeling, and automated decision-making, propelling them into a new era of technological advancement.







NVIDIA’s server solutions leverage advanced GPU architectures, like the latest Ampere series, to deliver unparalleled processing power and efficiency. These servers are optimized for a variety of applications, including deep learning, scientific computation, and large-scale data analytics, providing the necessary tools to drive innovation and accelerate discovery in any organization. With NVIDIA’s commitment to continuous advancement in AI technology, their servers represent a cornerstone for enterprises aiming to harness the power of artificial intelligence effectively and sustainably.
We offer two specialized General AI hardware infrastructures tailored for distinct needs: our Production-Ready solution and our R&D-Focused option. The Production-Ready infrastructure is engineered for maximum reliability and compliance, ideal for critical environments where uptime is crucial, such as in healthcare and finance. It is robust but comes at a higher cost. Conversely, our R&D-Focused infrastructure is more budget-friendly, designed for experimental and developmental purposes where full production compliance isn’t a necessity. This setup is perfect for organizations looking to innovate and test AI models economically, allowing them to scale their operations to a Production-Ready environment when needed.
Designed for high-stakes environments, this infrastructure combines robust, high-performance configurations to ensure continuous, reliable operation. Ideal for critical sectors like healthcare and finance, it minimizes downtime risks despite its higher cost.
This cost-effective R&D infrastructure supports innovation without the expense of full production compliance. It’s ideal for developing and testing AI models in pre-production phases, offering flexibility but not suited for all production requirements.
Equipped with Nvidia L4 cards offering excellent value for money. Ideal for basic AI tasks and small model development, these cards ensure reliable and economical performance for standard machine learning and data analysis applications. Perfect for inference on models like LLaMA 3 7B or Mistral, they are ideal for small-scale deployments (These cards do not support MIG). This offering is mainly recommended for the inference of small models.
2 recommended configurations:
Compatible with GPU Virtualization, very practical for small production or sandbox development.

3 recommended configurations:
Compatible with GPU Virtualization, very practical for small production or sandbox development.
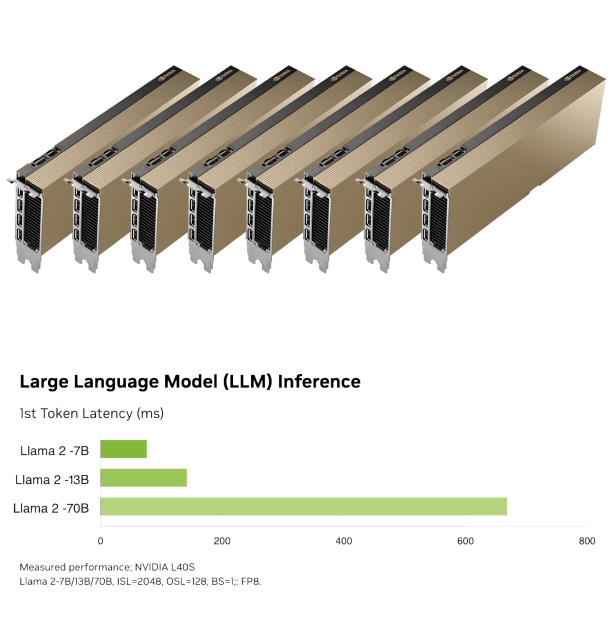
3 recommended configurations:
Compatible with GPU Virtualization, very practical for small production or sandbox development.
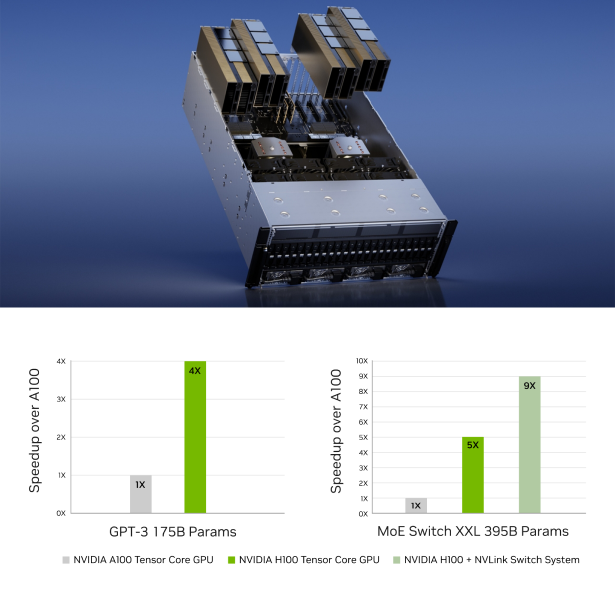
L4 2
2x NVIDIA L4 GPUs Tensor Core GPU
48 GB
484 TFLOPS
Machine Learning (dev) / Quantized LLMs
L4 4
4x NVIDIA L4 GPUs Tensor Core GPU
96 GB
968 TFLOPS
small LLM inference (ex. llama3 8B, mixtral 22B)
L40s 2
2x NVIDIA L40s GPUs
96 GB
724 TFLOPS
medium LLM inference (ex. llama3 70B, mixtral 8x7B)
L40s 4
4x NVIDIA L40s GPUs
192 GB
1 448 TFLOPS
large LLM inference (ex. mixtral 8x22B)
L40s 8
8x NVIDIA L40s GPUs
384 GB
2 896 TFLOPS
Fine-tuning / medium LLM inference (ex. llama3 70B, mixtral 8x7B)
H100 1
1x NVIDIA H100 GPUs Tensor Core GPU
80 GB
1 513 TFLOPS
small LLM Fine-tuning / Inference
H100 2
2x NVIDIA H100 GPUs Tensor Core GPU
160 GB
3 026 TFLOPS
medium LLM Fine-tuning / Inference
H100 4
4x NVIDIA H100 GPUs Tensor Core GPU
320 GB
6 052 TFLOPS
large LLMs inference
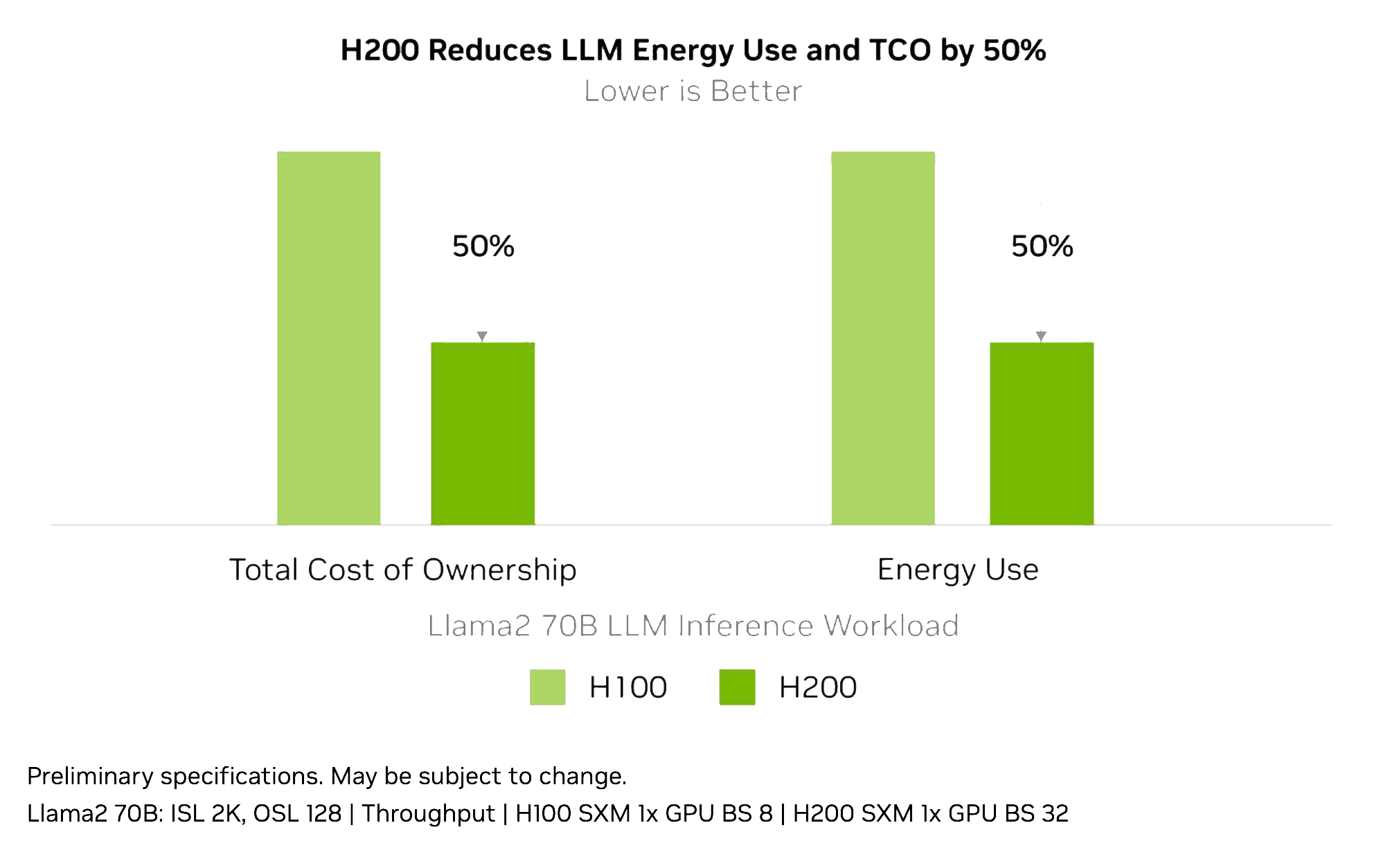
H200 1
1x NVIDIA H200 GPUs Tensor Core GPU
141 GB
1 979 TFLOPS
medium LLM Fine-tuning / Inference
H200 2
2x NVIDIA H200 GPUs Tensor Core GPU
282 GB
3 958 TFLOPS
large LLMs inference / Fine-tuning
H200 4
4x NVIDIA H200 GPUs Tensor Core GPU
564 GB
7 916 TFLOPS
large LLMs inference / Fine-tuning
H200 8
8x NVIDIA H200 GPUs Tensor Core GPU
1 128 GB
15 832 TFLOPS
large LLMs Fine-tuning / Multi-large LLM inference
B200 1
1x NVIDIA B200 GPUs Tensor Core GPU
180 GB
4 500 TFLOPS
medium LLM Fine-Tuning / Inference
B200 2
2x NVIDIA B200 GPUs Tensor Core GPU
360 GB
9 000 TFLOPS
Large LLMs inference / Fine Tuning
B200 4
4x NVIDIA B200 GPUs Tensor Core GPU
720 GB
18 000 TFLOPS
Large LLMs inference / Fine Tuning
B200 8
8x NVIDIA B200 GPUs Tensor Core GPU
1 440 GB
36 000 TFLOPS
Large LLM Fine Tuning / Multi Large LLMs inference


Ideal for long-term needs, purchasing equipment allows businesses to become the outright owners after the transaction is complete. This method is cost-effective over time, particularly for equipment that is essential and frequently used. It also eliminates any restrictions on usage that are common with other acquisition methods.
This option provides the flexibility of using the latest equipment without the upfront costs associated with purchasing. Under a lease agreement, clients can use the equipment for a predetermined period while making regular payments. This is particularly advantageous for temporary projects or when upgrading equipment frequently. At the end of the lease term, the equipment is returned, offering the opportunity to renew, upgrade, or terminate based on current needs.
Designed for companies that require specialized equipment but only on an occasional basis, this method ties the cost directly to the usage rate. It is an economically sensible choice when avoiding large capital expenditures and maintaining cash flow are priorities. Pay-per-Use ensures clients pay only for what they use, making it an ideal option for equipment that may not be needed continuously.

We offer innovative Full-stack AI platforms that makes AI infrastructure effortless and powerful. Harnessing NVIDIA’s H100 and H200 GPUs, our solutions deliver top-tier performance for your AI needs. Our platforms adapt seamlessly, scaling from small projects to extensive AI applications, providing flexible and reliable hosting. From custom design to deployment and ongoing support, we ensure smooth operation every step of the way. In today’s fast-paced AI world, a robust infrastructure is key. At Iguana Solutions, we’re not just providing technology; we’re your partner in unlocking the full potential of your AI initiatives. Explore how our Gen AI platforms can empower your organization to excel in the rapidly evolving realm of artificial intelligence.
We offer innovative Gen AI platforms that make AI infrastructure effortless and powerful. Harnessing NVIDIA’s H100 and H200 GPUs, our solutions deliver top-tier performance for your AI needs. Our platforms adapt seamlessly, scaling from small projects to extensive AI applications, providing flexible and reliable hosting. From custom design to deployment and ongoing support, we ensure smooth operation every step of the way. In today’s fast-paced AI world, a robust infrastructure is key. At Iguana Solutions, we’re not just providing technology; we’re your partner in unlocking the full potential of your AI initiatives. Explore how our Gen AI platforms can empower your organization to excel in the rapidly evolving realm of artificial intelligence.
Embark on your DevOps journey with Iguana Solutions and experience a transformation that aligns with the highest standards of efficiency and innovation. Our expert team is ready to guide you through every step, from initial consultation to full implementation. Whether you’re looking to refine your current processes or build a new DevOps environment from scratch, we have the expertise and tools to make it happen. Contact us today to schedule your free initial consultation or to learn more about how our tailored DevOps solutions can benefit your organization. Let us help you unlock new levels of performance and agility. Don’t wait—take the first step towards a more dynamic and responsive IT infrastructure now.
